步骤一:准备编译环境
关闭防火墙。
运行systemctl status firewalld命令,查看当前防火墙的状态。
如果防火墙的状态参数是inactive,则防火墙为关闭状态。
如果防火墙的状态参数是active,则防火墙为开启状态。
关闭防火墙。如果防火墙为关闭状态可以忽略此步骤。
如果您想临时关闭防火墙,需要运行以下命令:
systemctl stop firewalld
说明 临时关闭防火墙后,如果Linux实例重启,则防火墙将会自动开启。
如果您想永久关闭防火墙,需要依次运行以下命令:
关闭防火墙。
systemctl stop firewalld
实例开机时,禁止启动防火墙服务。
systemctl disable firewalld
关闭SELinux。
运行getenforce命令查看SELinux的当前状态。
如果SELinux状态参数是Disabled,则SELinux为关闭状态。
如果SELinux状态参数是Enforcing,则SELinux为开启状态。
关闭SELinux。如果SELinux为关闭状态可以忽略此步骤。
步骤二:安装Nginx
运行以下命令安装Nginx。
yum -y install nginx
运行以下命令查看Nginx版本。
nginx -v
返回结果如下所示,表示Nginx安装成功。
nginx version: nginx/1.20.1
步骤三:安装MySQL
运行以下命令更新YUM源。
rpm -Uvh http://dev.mysql.com/get/mysql57-community-release-el7-9.noarch.rpm
运行以下命令安装MySQL。
说明 如果您使用的操作系统内核版本为el8,可能会提示报错信息No match for argument。您需要先运行命令yum module disable mysql禁用默认的MySQL模块,再安装MySQL。
yum -y install mysql-community-server
运行以下命令查看MySQL版本号。
mysql -V
返回结果如下所示,表示MySQL安装成功。
mysql Ver 14.14 Distrib 5.7.36, for Linux (x86_64) using EditLine wrapper
运行以下命令启动MySQL。
systemctl start mysqld
依次运行以下命令设置开机启动MySQL。
systemctl enable mysqld
systemctl daemon-reload
步骤四:安装PHP
更新YUM源。
运行以下命令添加epel源。
yum install \
https://repo.ius.io/ius-release-el7.rpm \
https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm
运行以下命令添加Webtatic源。
rpm -ivh https://mirror.webtatic.com/yum/el7/webtatic-release.rpm
运行以下命令安装PHP。
yum -y install php71w-devel php71w.x86_64 php71w-cli.x86_64 php71w-common.x86_64 php71w-gd.x86_64 php71w-ldap.x86_64 php71w-mbstring.x86_64 php71w-mcrypt.x86_64 php71w-pdo.x86_64 php71w-mysqlnd php71w-fpm php71w-opcache php71w-pecl-redis php71w-pecl-mongodb
运行以下命令查看PHP版本。
php -v
返回结果如下所示,表示安装成功。
PHP 7.0.33 (cli) (built: Dec 6 2018 22:30:44) ( NTS )
Copyright (c) 1997-2017 The PHP Group
Zend Engine v3.0.0, Copyright (c) 1998-2017 Zend Technologies
with Zend OPcache v7.0.33, Copyright (c) 1999-2017, by Zend Technologies
步骤五:配置Nginx
运行以下命令备份Nginx配置文件。
cp /etc/nginx/nginx.conf /etc/nginx/nginx.conf.bak
修改Nginx配置文件,添加Nginx对PHP的支持。
说明 若不添加此配置信息,后续您使用浏览器访问PHP页面时,页面将无法显示。
运行以下命令打开Nginx配置文件。
vim /etc/nginx/nginx.conf
按i进入编辑模式。
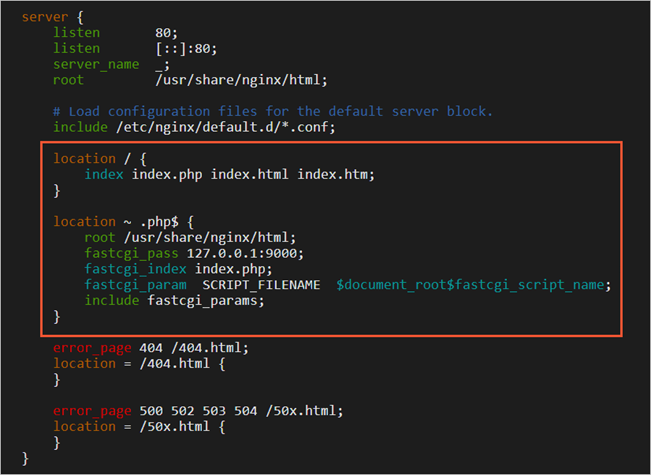
在server大括号内,修改或添加下列配置信息。除下面提及的需要添加或修改的配置信息外,其他配置保持默认值即可。
添加或修改location /配置信息。
location / {
index index.php index.html index.htm;
}
添加或修改location ~ .php$配置信息。
#添加下列信息,配置Nginx通过fastcgi方式处理您的PHP请求。
location ~ .php$ {
root /usr/share/nginx/html; #将/usr/share/nginx/html替换为您的网站根目录,本文使用/usr/share/nginx/html作为网站根目录。
fastcgi_pass 127.0.0.1:9000; #Nginx通过本机的9000端口将PHP请求转发给PHP-FPM进行处理。
fastcgi_index index.php;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
include fastcgi_params; #Nginx调用fastcgi接口处理PHP请求。
}
添加或修改配置信息后,文件内容如下图所示:
按下Esc键后,输入:wq并回车以保存关闭配置文件。
运行以下命令启动Nginx服务。
systemctl start nginx
运行以下命令设置Nginx服务开机自启动。
systemctl enable nginx
步骤六:配置MySQL
运行以下命令查看/var/log/mysqld.log文件,获取并记录root用户的初始密码。
grep ‘temporary password’ /var/log/mysqld.log
命令行返回结果如下,其中ARQTRy3+n8W为MySQL的初始密码。在下一步重置root用户密码时,会使用该初始密码。 2021-11-10T07:01:26.595215Z 1 [Note] A temporary password is generated for root@localhost: ARQTRy3+n8W
运行以下命令配置MySQL的安全性。
mysql_secure_installation
输入MySQL的初始密码。
说明 在输入密码时,系统为了最大限度的保证数据安全,命令行将不做任何回显。您只需要输入正确的密码信息,然后按Enter键即可。
Securing the MySQL server deployment.
Enter password for user root: #输入上一步获取的root用户初始密码
为MySQL设置新密码。
The existing password for the user account root has expired. Please set a new password.
New password: #输入新密码。长度为8至30个字符,必须同时包含大小写英文字母、数字和特殊符号。特殊符号包含()` ~!@#$%^&*-+=|{}[]:;‘<>,.?/
Re-enter new password: #确认新密码。
The ‘validate_password’ plugin is installed on the server.
The subsequent steps will run with the existing configuration
of the plugin.
Using existing password for root.
Estimated strength of the password: 100 #返回结果包含您设置的密码强度。
Change the password for root ? ((Press y|Y for Yes, any other key for No) :Y #您需要输入Y以确认使用新密码。
新密码设置完成后,需要再次验证新密码。
New password:#再次输入新密码。
Re-enter new password:#再次确认新密码。
Estimated strength of the password: 100
Do you wish to continue with the password provided?(Press y|Y for Yes, any other key for No) :Y #您需要输入Y,再次确认使用新密码。
输入Y删除匿名用户。
Remove anonymous users? (Press y|Y for Yes, any other key for No) :Y
Success.
输入Y禁止使用root用户远程登录MySQL。
Disallow root login remotely? (Press y|Y for Yes, any other key for No) :Y
Success.
输入Y删除test库以及用户对test库的访问权限。
Remove test database and access to it? (Press y|Y for Yes, any other key for No) :Y
- Dropping test database…
Success. - Removing privileges on test database…
Success.
输入Y重新加载授权表。
Reload privilege tables now? (Press y|Y for Yes, any other key for No) :Y
Success.
All done!
步骤七:配置PHP
新建并编辑phpinfo.php文件,用于展示PHP信息。
运行以下命令新建phpinfo.php文件。
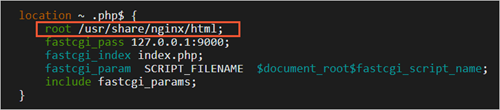
vim <网站根目录>/phpinfo.php
<网站根目录>是您在nginx.conf配置文件中location ~ .php$大括号内,配置的root参数值,如下图所示。
本文配置的网站根目录为/usr/share/nginx/html,因此需要运行以下命令新建phpinfo.php文件:
vim /usr/share/nginx/html/phpinfo.php
按i进入编辑模式。
输入下列内容,函数phpinfo()会展示PHP的所有配置信息。
按Esc键后,输入:wq并回车,保存关闭配置文件。
运行以下命令启动PHP-FPM。
systemctl start php-fpm
运行以下命令设置PHP-FPM开机自启动。
systemctl enable php-fpm
步骤八:测试访问LNMP配置信息页面
在本地Windows主机或其他具有公网访问能力的Windows主机中,打开浏览器。
在浏览器的地址栏输入http:///phpinfo.php进行访问。
访问结果如下图所示,表示LNMP环境部署成功。
后续步骤
测试访问LNMP配置信息页面后,建议您运行以下命令将phpinfo.php文件删除,消除数据泄露风险。
rm -rf <网站根目录>/phpinfo.php
其中,<网站根目录>需要替换为您在nginx.conf中配置的网站根目录。本文配置的网站根目录为/usr/share/nginx/html,因此需要运行以下命令:
rm -rf /usr/share/nginx/html/phpinfo.php
常见问题
如何使用其他版本的Nginx服务器?
使用浏览器访问Nginx开源社区获取对应的Nginx版本的下载链接。
请根据您的个人需求,选择对应的Nginx版本。本章节以Nginx 1.8.1为例。
远程连接需要部署LNMP环境的ECS实例。
运行wget命令下载Nginx 1.8.1。您可以通过Nginx开源社区直接获取对应版本的安装包URL,然后通过wget URL的方式将Nginx安装包下载至ECS实例。例如,Nginx 1.8.1的下载命令如下:
wget http://nginx.org/download/nginx-1.8.1.tar.gz
运行以下命令,安装Nginx相关依赖。
yum install -y gcc-c++
yum install -y pcre pcre-devel
yum install -y zlib zlib-devel
yum install -y openssl openssl-devel
运行以下命令,解压Nginx 1.8.1安装包,然后进入Nginx所在的文件夹。
tar zxvf nginx-1.8.1.tar.gz
cd nginx-1.8.1
依次运行以下命令,编译源码。
./configure \
–user=nobody \
–group=nobody \
–prefix=/usr/local/nginx \
–with-http_stub_status_module \
–with-http_gzip_static_module \
–with-http_realip_module \
–with-http_sub_module \
–with-http_ssl_module
make && make install
运行以下命令,进入Nginx的sbin目录,然后启动Nginx。
cd /usr/local/nginx/sbin/
./nginx
在本地主机中,使用浏览器访问ECS实例公网IP。
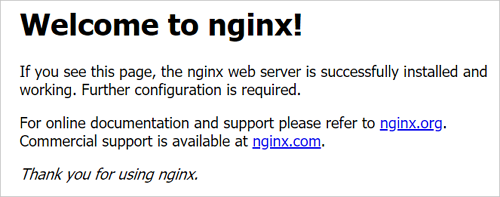
出现如下图所示的页面,表示Nginx已成功安装并启动。



 本文配置的网站根目录为/usr/share/nginx/html,因此需要运行以下命令新建phpinfo.php文件:
本文配置的网站根目录为/usr/share/nginx/html,因此需要运行以下命令新建phpinfo.php文件: